

The MS Excel® “=RAND( )” function is one of the two commonly used to generate a random decimal number from zero to one in an Excel cell. Another one is “=RANDBETWEEN( )”, which generates a random integer in the range specified. Read on ….
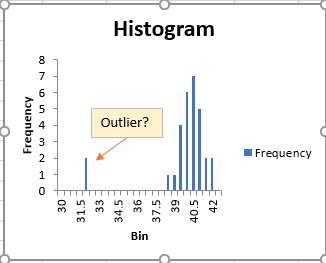
It is quite difficult to identify suspected values visually as outliers from a set of data collected. Very often, an outlier statistic test is to be performed before further action such as deletion of such data or further testing, as we do not wish to discard such data without sound statistical justification. Read on …
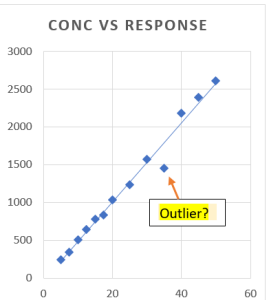
In repeated chemical analysis which assumes normal probability distribution, we may find some extreme (i.e. the biggest or smallest result) is a suspect which seems to be quite different from the rest of the data set. In other words, this result does not seem to belong to the distribution of the rest of the data. This suspect value is called an outlier. Read more ….

Analysis of variance (ANOVA) is useful in laboratory data analysis for significance testing. It however, has certain assumptions that must be met for the technique to be used appropriately. Their assumptions are somewhat similar to those of regression because both linear regression and ANOVA are really just two ways of analysis the data that use the general linear model. Departures from these assumptions can seriously affect inferences made from the analysis of variance.
The assumptions are:
The outcome variables should be continuous, measured at the interval or ratio level, and are unbounded or valid over a wide range. The factor (group variables) should be categorical (i.e. being an object such as Analyst, Laboratory, Temperature, etc.);
Each value of the outcome variable is independent of each other value to avoid biases. There should not have any influence of the data collected. That means the samples of the group under comparison must be randomly and independently drawn from the population.
The continuous variable is approximately normally distributed within each group. This distribution of the continuous variable can be checked by creating a histogram and by a statistical test for normality such as the Anderson-Darling or the Kolmogorov-Smirnov. However, the one-way ANOVA F-test is fairly robust against departures from the normal distribution. As long as the distributions are not extremely different from a normal distribution, the level of significance of the ANOVA F-test is usually not greatly affected by lack of normality, particularly for large samples.
The variance of each of the groups should be approximately equal. This assumption is needed in order to combine or pool the variances within the groups into a single within-group source of variation SSW. The Levene statistic test can be used to check variance homogeneity. The null hypothesis is that the variance is homogeneous, so if the Levene statistic are not statistically significant (normally at alpha < 0.05), the variances are assumed to be sufficiently homogeneous to proceed in the data analysis.
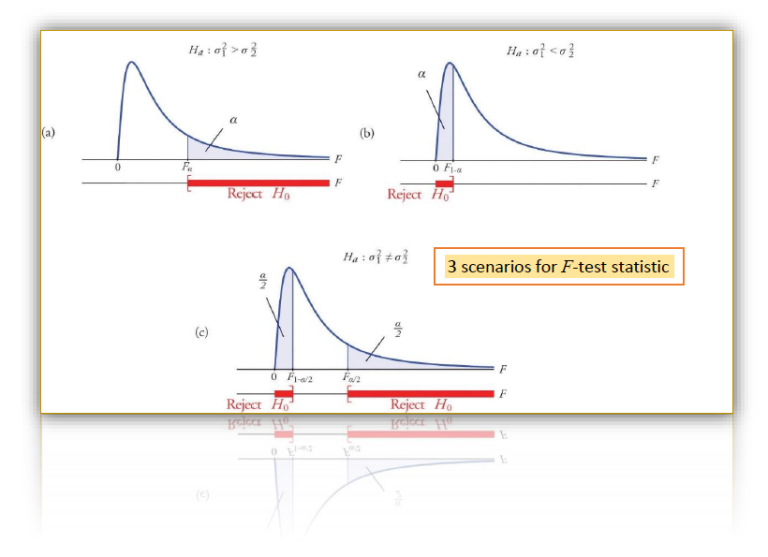
The Fisher F-test statistic is based on the ratio of two experimentally observed variance, which are squared standard deviations. Therefore, it is useful to test whether two standard deviations s1 and s2, calculated from two independent data sets are significantly different in terms of precision from each other. Read more …a