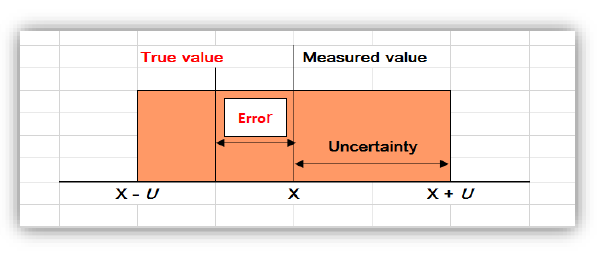
Few course participants had expressed their opinions that the subject of hypothesis testing was quite abstract and they have found it hard to grasp its concept and application. I thought otherwise. Perhaps let’s go through its basics again.
We know the study of statistics can be broadly divided into descriptive statistics and inferential or analytical statistics. Descriptive statistical techniques (like frequency distributions, mean, standard deviation, variance, central tendency, etc.) are useful for summarizing data obtained from samples, but they also provide tools for more advanced data analysis related to a broader picture on population where the samples are drawn from, through the application of probability theories in sampling distributions and confidential intervals. We use the analysis of sample data variation collected to infer what the situation of its population parameter is to be.
A hypothesis is an educated guess about something around us, as long as we can put it to test either by experiment or just observations. So, hypothesis testing is a statistical method that is used in making statistical decisions using experimental data. It is basically an assumption that we make about the population parameter. In the nutshell, we want to:
- make a statement about something
- collect sample data relating to the statement
- if given that the statement is true and the sample outcome is unlikely, we shall realize that the statement probably is not true.
In short, we have to make decisions about the hypothesis. The decisions are to decide if we should accept the null hypothesis or if we should reject the null hypothesis with certain level of significance. Therefore, every test in hypothesis testing produces a significance value for that particular test. In hypothesis testing, if the significance value of the test is greater than the predetermined significance level, then we accept the null hypothesis. If the significance value is less than the predetermined value, then we should reject the null hypothesis.
Let us have a simple illustration.
Assume we want to know if a particular coin is fair. We can give a statistical statement (null hypothesis, Ho) that it is a fair coin. The alternative hypothesis, H1 or Ha, of course, is that the coin is not a fair coin.
If we were to toss the coin, say 30 times and got heads 25 times. We take this as an unlikely outcome given it is a fair coin, we can reject the null hypothesis saying that it is a fair coin.
In the next article, we shall discuss the steps to be taken in carrying out such hypothesis testing with a set of laboratory data.